Introduction
This technology review details about multimodal natural language content analysis techniques and, why the approach is better over the siloed text/audio/ video only natural language content analysis.
Business Need
An ever-increasing share of human interaction, communication and culture is recorded as digital text. In enterprises alone, increasing adoption of digital communication channels is expected to create 70 to 80% of unstructured data1. What does this data tell us about the various business problems we can solve and, opportunities we can create?
A few scenarios:
1. What does a patient response to a medication prescription say about the patient’s medication adherence and the downstream cost of care impact?
2. What is the difference in customer behavior to wait times on telephone lines?
3. What can I learn from my customer response to my various product offerings and, how can I utilize it to better align my products and market messaging to improve my sales?
4. Why are my employees having high communication about the new product development initiative? How can I improve my team’s productivity by better collaboration initiatives? Do I need new communication tools, etc.?
In all cases above, if we can capture video, audio and/or text interactions together, we can get much more insight than what just one of them can offer. If we take the first scenario for example, by capturing a patient’s video, audio and text interaction data, we can infer that the patient is surprised that he was prescribed antibiotics. Though the patient has said “OK” as a response to the prescription, his facial response might show surprise or disappointment and, the audio recording can show intonation that shows disappointment when the word “ok” was uttered.
Here’s a 14-minute interaction between a doctor and a patient and how sentiment analysis can be different based on the modality:

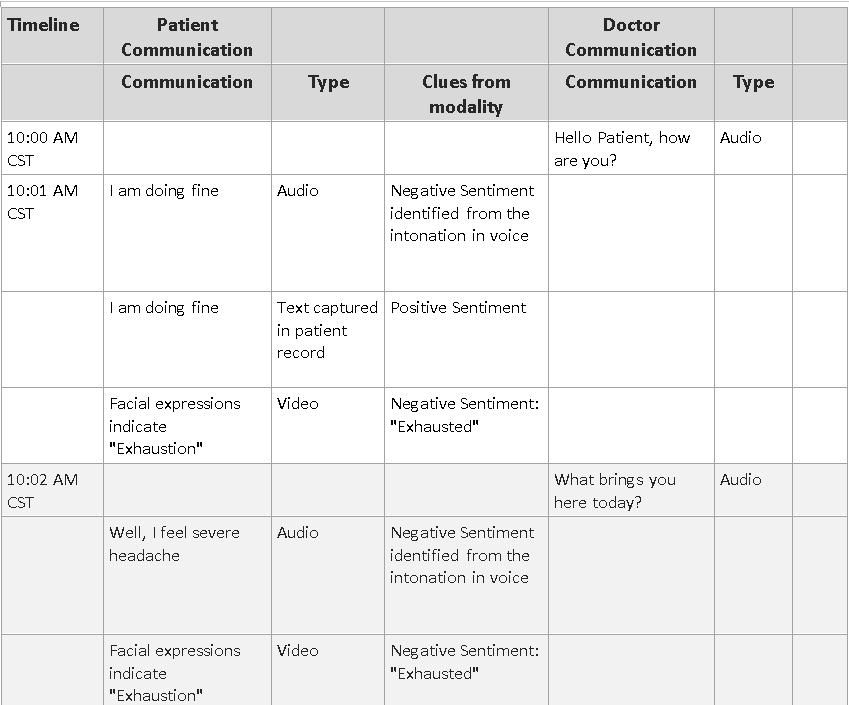

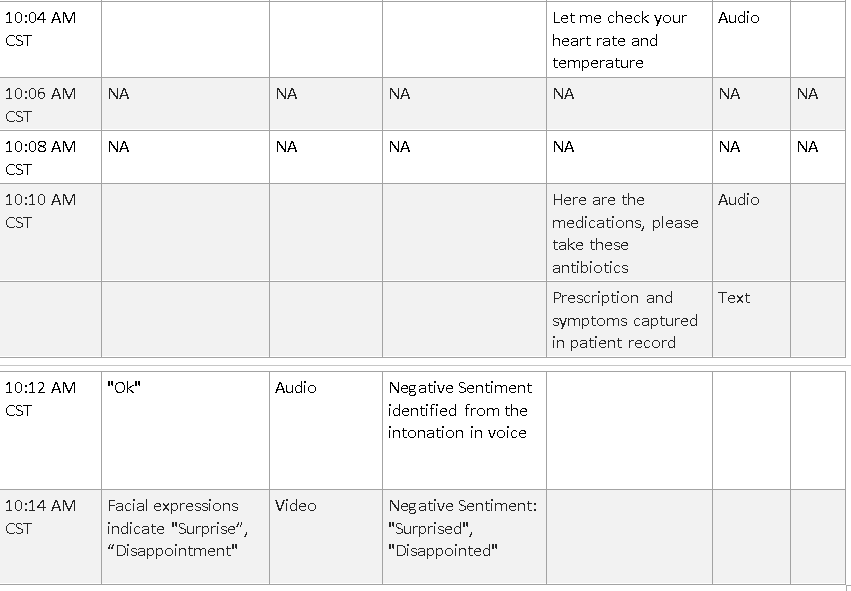
As we can notice, depending the modality, the same patient communication could give a totally different sentiment analysis.
Further in cases where a modality fails to capture accurate information, the information from other modalities can be used as fillers.
Technology Review
1) Visual Content Analysis Techniques
Library: face recognition available in Python 2.7 and above 3, 4, 5, 6
- This library provides the following:
o Face detection
o Facial recognition
o Emotion detection
- Sample code3:
To install Pip, install face recognition
Facial recognition
face_locations = face_recognition.face_locations(image)
top, right, bottom, left = face_locations[0]
face_image = image[top:bottom, left:right]
top, right, bottom, left = face_locations[0]
face_image = image[top:bottom, left:right]
encoding_1 = face_recognition.face_encodings(image1)[0]
encoding_2 = face_recognition.face_encodings(image1)[0]
results = face_recognition.compare_faces([encoding_1], encoding_2,tolerance=0.50)
encoding_2 = face_recognition.face_encodings(image1)[0]
results = face_recognition.compare_faces([encoding_1], encoding_2,tolerance=0.50)
Emotion detection:
model = load_model(“./emotion_detector_models/model.hdf5”)
predicted_class = np.argmax(model.predict(face_image)
predicted_class = np.argmax(model.predict(face_image)
Java, .Net C# and other technologies also offer facial recognition libraries.
2) Audio Content Analysis Techniques
Python Library: pyAudioAnalysis 8
Features offered:
· Extract audio features and representations (e.g. mfccs, spectrogram, chromagram)
· Classify unknown sounds
· Train, parameter tune and evaluate classifiers of audio segments
· Detect audio events and exclude silence periods from long recordings
· Perform supervised segmentation (joint segmentation — classification)
· Perform unsupervised segmentation (e.g. speaker diarization)
· Extract audio thumbnails
· Train and use audio regression models (example application: emotion recognition)
· Apply dimensionality reduction to visualize audio data and content similarities
Sample code 8:
from pyAudioAnalysis import audioTrainTest as aT
aT.featureAndTrain([“classifierData/music”,”classifierData/speech”], 1.0, 1.0, aT.shortTermWindow, aT.shortTermStep, “svm”, “svmSMtemp”, False)
aT.fileClassification(“data/doremi.wav”, “svmSMtemp”,”svm”)
Result:
(0.0, array([ 0.90156761, 0.09843239]), [‘music’, ‘speech’])
3) Text Content Analysis / NLP Techniques 11
Python Libraries:
- META 12
- NLTK 9, 10
- The Prince: TextBlob
- The Mercenary: Stanford CoreNLP
- The Usurper: spaCy
- The Admiral: gensim
4) Multi-model Content Analysis Techniques
Approach suggested:
1) Capture a human interaction in all three modes where possible.
2) Perform data mining and sentiment analysis for the same content at the same time frame across modalities (text, speech, image/ video)
3) Use the mix of the content to infer. An example approach using deep learning is provided in the following diagram 13
4) Even without deep learning, the individual modal approaches specified in the 1,2,3 in this paper above can be merged to together come up with a solution that aggregates the data from different modalities and perform data mining and semantic analysis. The 14-minute Doctor- patient interaction table provided in this paper details the abstract idea.
References
2. Multimodal sentiment analysis
Comments
Post a Comment